Originally published on the amazing Matt Boyle's byteSizeGo
Sometime around the middle of January, I stumbled across One Billion Rows Challenge. I had a lot of fun working on this. I started with an execution time of > 6min and finished at about 14s. Here’s how I went about it.
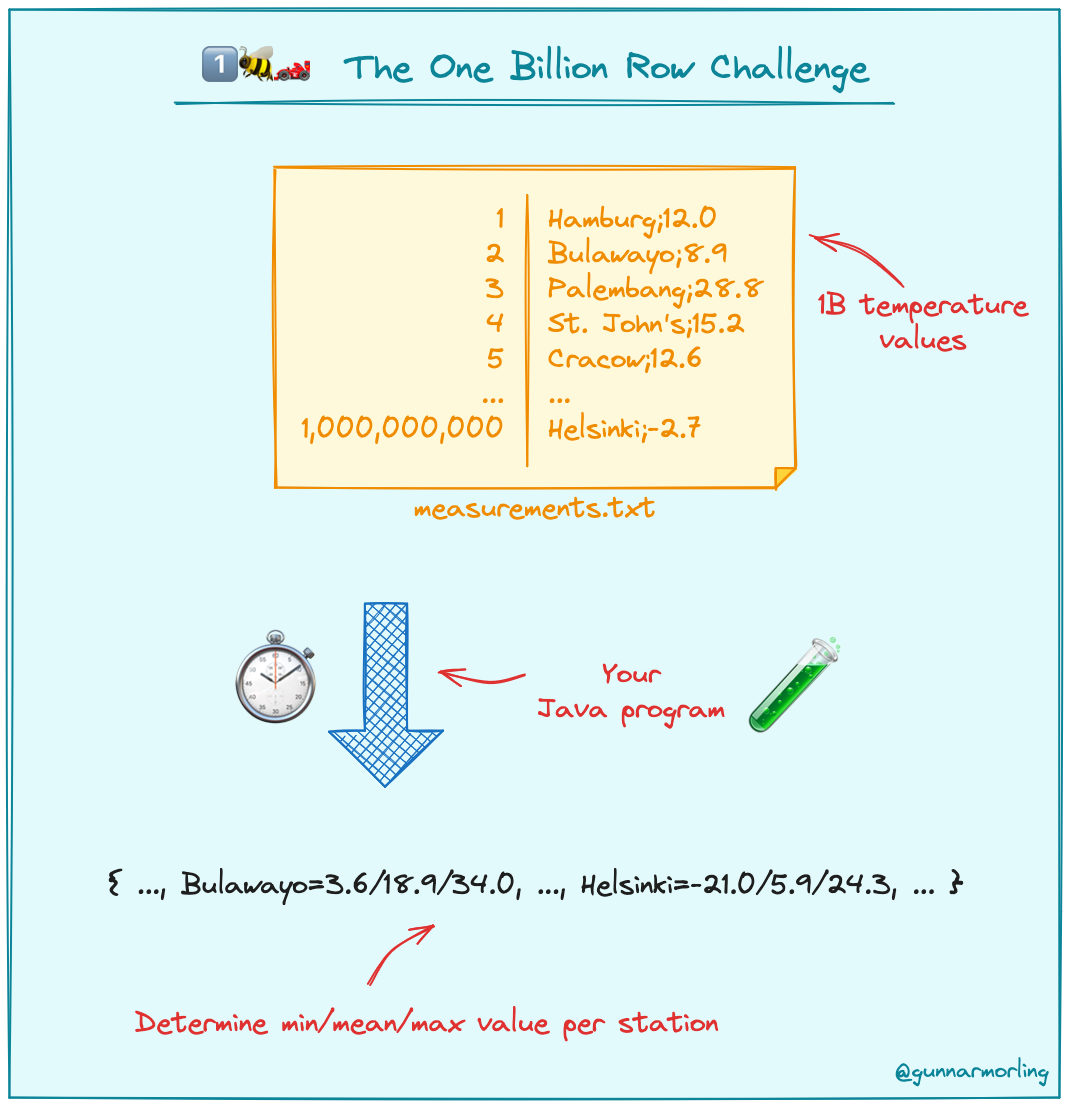
What is the 1BRC challenge?
Input: A text file containing temperature values for a range of weather stations. Each row is one measurement in the format <string: station name>;<float: measurement>.
Output: For each unique station, find the minimum, average and maximum temperature recorded and emit the final result on STDOUT in station name’s alphabetical order with the format {<station name>:<min>/<average>/<max>;<station name>:<min>/<average>/<max>}.
Known constrains we are working with:
- the temperature value is within [-99.9, 99.9] range.
- the temperature value only has exactly one fractional digit.
- the byte length of station name is within [1,100] range.
- there will be a maximum of 10,000 unique station names.
- rounding of temperature values must be done using the semantics of IEEE 754 rounding-direction "roundTowardPositive”.
Sounds simple enough. What’s the catch? The input file has a billion rows, thats 1,000,000,000. How big is a Billion? If you started counting to 1 billion at the rate 3 seconds per number, it would take you about 95.1 years!
The challenge is to process the file to print the output in the least amount of time possible. Its summarised nicely in this picture, credits @gunnarmorling.
Tools I am working with
The challenge was initially introduced for Java, but folks started trying it out in different languages. You can checkout the discussion about 1BRC in Golang.
I solved this using Golang 1.21. All benchmarks are run on Apple M1 Pro, 2021 model with 16GB memory and 10 vCPU. The input file with a billion rows is about 16GB.
GitHub repository with my solution is here.
I took the approach of solving this iteratively. Doing so helped me keep track of my progress. You can find all iterations documented in my repo’s README. With each iteration, I focused on optimising one of these three areas:
- Data Structures
- Concurrency
- Reading file
Now that all of that is out of the way, let’s dive in!
#0: Baseline implementation
I started with a naive implementation to establish a baseline runtime. This first iteration did not make use of any concurrency.
Reading File: line by line
In the input file, each line can be processed independently. So, I started by reading the file line by line. For this I used bufio’s Scanner with the default split function, ScanLines, a pretty standard way to read a file line by line in Golang.
Scanner is a handy interface that reads from file and returns contents upto the split defined. For us, this means that the new line character \n will not be returned in each line scanned, so we won’t have to handle it separately (foreshadowing: this is also where the problem lies with this method of reading the file).
Data Structure: map to store all temperature values recorded for each unique station
Output requires, minimum, maximum and average temperatures recorded in each city. So I initially started with a map that stored all temperatures recorded for each unique station. Each station is stored in string type and each temperature is stored in float64 type, making the map signature map[string][]float64. As each line is read from the file, values are added to this map accordingly.
After the entire file contents are read and the map is constructed, we can iterate through each key value pair in the map to calculate the min, max and average temperatures and find the station names’ alphabetical order. Once we have these two pieces of information, we can format the final output.
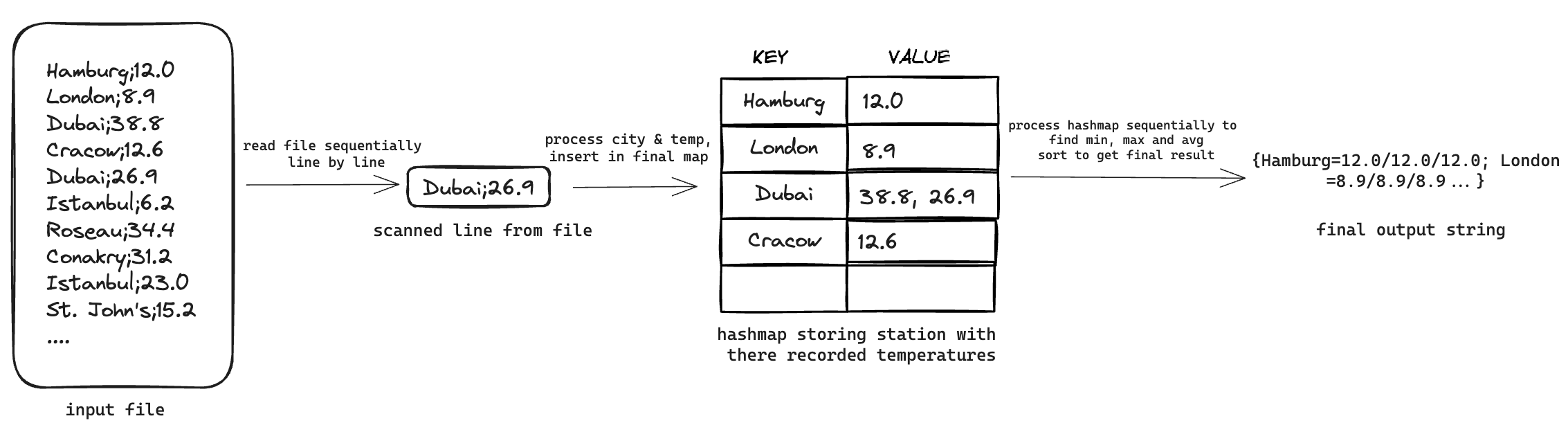
Storing all temperatures recorded for a city is a rather poor choice as we don’t actually need all individual temperatures. We will see later how we can fix this by using a different data structure.
As expected, this performs rather poorly, execution takes ~6 min.
go run main.go 227.57s user 36.91s system 70% cpu 6:13.15 total
Now that we have something we can work upon, lets get started.
#1: Concurrency: process each station’s min, max and average temperature in a separate goroutine
The first place I introduced concurrency was in the last stage of execution. For each city in the map, I instantiated a new goroutine to process each city’s min, max and average temperatures.
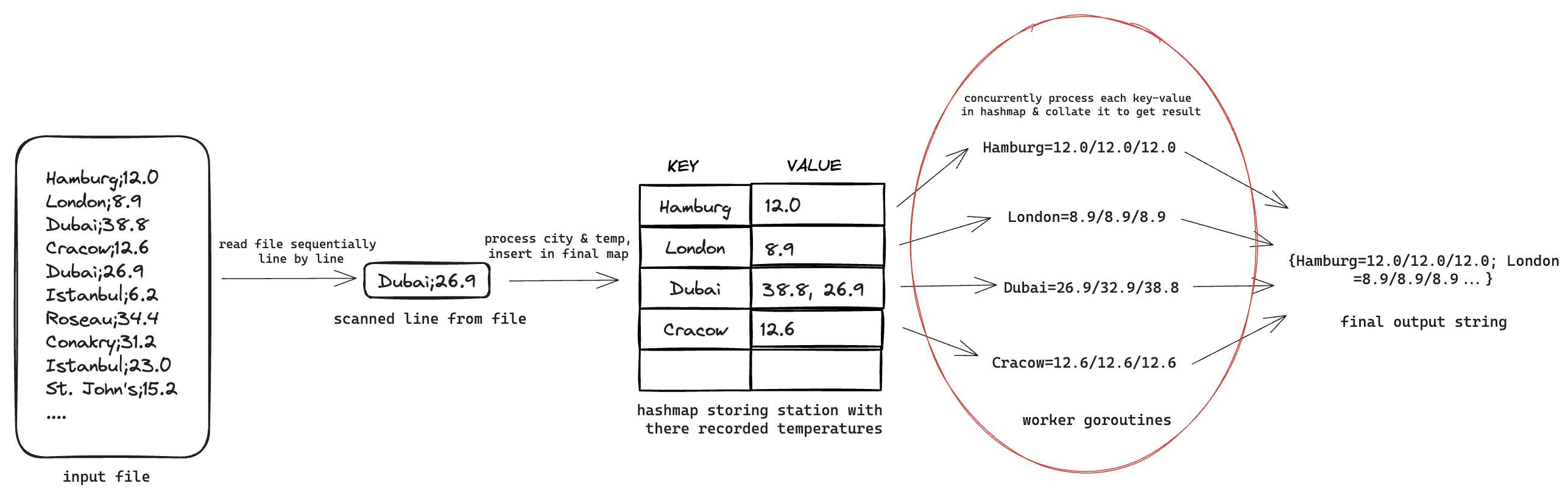
Code upto this point can be found here. This improves performance, by ~100s.
go run main.go 229.07s user 44.52s system 100% cpu 4:32.80 total
This is inefficient because we are spinning up too many goroutines, a maximum of 10,000, one for each station. The go scheduler is spending more time managing the goroutines than doing actual work. We will fix this in future iterations.
#2. Concurrency: decouple reading and processing of file contents
Currently we are reading a line from the file, parsing the station name and temperature and adding it to the map and then reading the next line. Doing this sequentially means we are not taking advantage of all CPU cores. Instead, we are reading a line, waiting to finish processing it before reading the next line.
To overcome this, I decoupled reading and processing of the read lines. I introduced two goroutines for this:
- a producer goroutine, responsible for scanning the lines.
- a consumer goroutine to process these read line.
To communicate between the two goroutines, ie, send the read lines from the producer to consumer goroutine, I used a channel.
The problem with unbuffered Channels
Channels are blocking. This is best explained in the book, Concurrency In Go by Katherine Cox-Buday:
Any goroutine that attempts to write to a channel that is full will wait until the channel has been emptied, and any goroutine that attempts to read from a channel that is empty will wait until at least one item is placed on it.
This means if we don’t use a buffered channel, when one goroutine is executing the other will be in blocked state. Using an unbuffered channel, the execution time indeed increased two fold:
go run main.go 419.12s user 245.88s system 118% cpu 9:12.91 total
CPU profiling the code, we can see the most amount of time is going in goroutine switches.
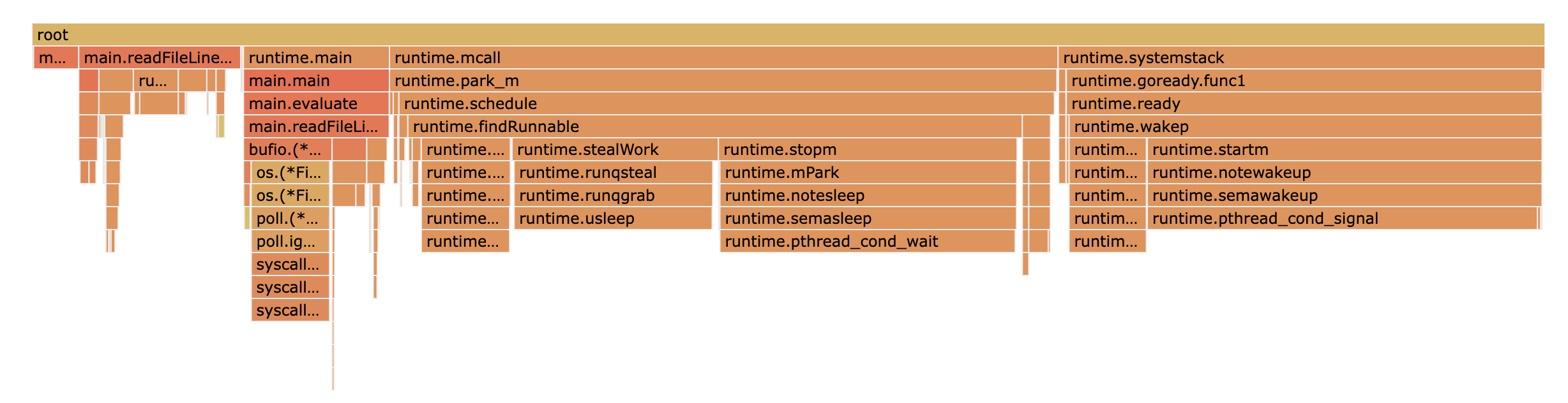
This makes sense and aligns with our understanding of unbuffered channels.
Using a buffered channel
Using a buffered channel with capacity 100, make(chan string, 100), we see the performance increase by 50% as compared to an unbuffered channel. Code and profiles till this point can be found here. I ran benchmarks with other capacity as well but found 100 to be the most efficient.
go run main.go 298.38s user 93.65s system 121% cpu 5:22.83 total
But, this is still slower than the previous iteration. Looking at the CPU profile, we notice that there is a significant time going in runtime.chanrecv.

This is expected, as we are sending 1,000,000,000 strings over the channel and then receiving the same in the consumer goroutine. Is there a way to reduce this number?
Sending a slice of lines on the channel
One way to reduce the number of items we send on the channel is to chunk a few lines together in a slice and then send it over the channel. This means the channel type will change from string to []string. I added 100 lines in a slice and send it over the buffered channel.
Since the channel type is slice, to avoid race condition we will need to create a copy of the slice to send it over to the channel. Alternatively we can use sync.Pool to reuse memory and limit memory allocation.
Go has a handy data race detector which can be used by adding -race flag when running code. You can read more about it here.
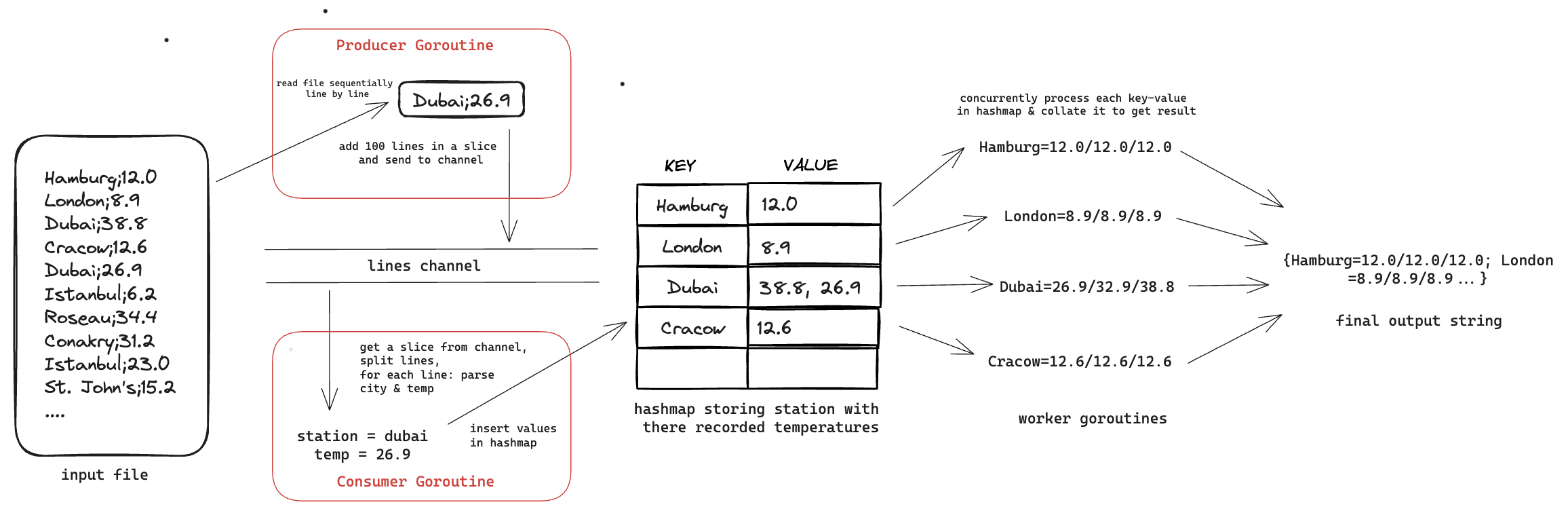
Code after these changes is in this state. Running this, execution time comes down by ~160s!
go run main.go 151.16s user 69.08s system 99% cpu 3:41.76 total
#3. Data Structure: Use int64 instead of float64
At this point, I added tests in the CI and realised my tests were failing due to how I was doing rounding. According to constraints, rounding should be done using the semantics of IEEE 754 rounding-direction "roundTowardPositive”.
I fixed this by parsing the temperature from string into int64. Doing summation in int64 and only converting to float64 after all calculations have been done.
This ended by improving performance considerably, by almost ~40s. Code can be found here.
go run main.go 178.14s user 48.20s system 131% cpu 2:51.50 total
Was surprised to see that there is such a significant performance improvement with this change on modern hardware. After researching about, this seems to explain why (reference):
results will vary wildly based on CPU architecture (individual ALU/FPU performance, as well as actual number of ALUs/FPUs available per core in superscalar designs which influences how many independent operations can execute in parallel).
This means your hardware will play a major factor in determining how much this change will contribute to performance improvement. A classic “it depends” moment.
#4. Data Structure: Store min, max, sum and count instead of all temperatures in map
In the baseline implementation we were using a map of type map[string][]float64 where for each station, we were storing all temperatures recorded.
This is wasteful as we don’t actually need to store all temperatures, we can simply store the minimum, maximum, sum and count of all temperatures. With this change we will see performance improvements for two reasons:
- Decreased memory allocation: We will go from storing a slice of around ~100,000
int64items, more or less (=1,000,000,000/10,000) to storing exactly 4int64items for each unique station. This significantly decreases our memory footprint. - Decreased number of goroutines: In the last step, we can get rid of spinning up goroutines to process temperatures of each station, as we are already processing the min, max and count values while constructing the map itself. This means the go scheduler needs to worry about a significantly lesser number of goroutines.
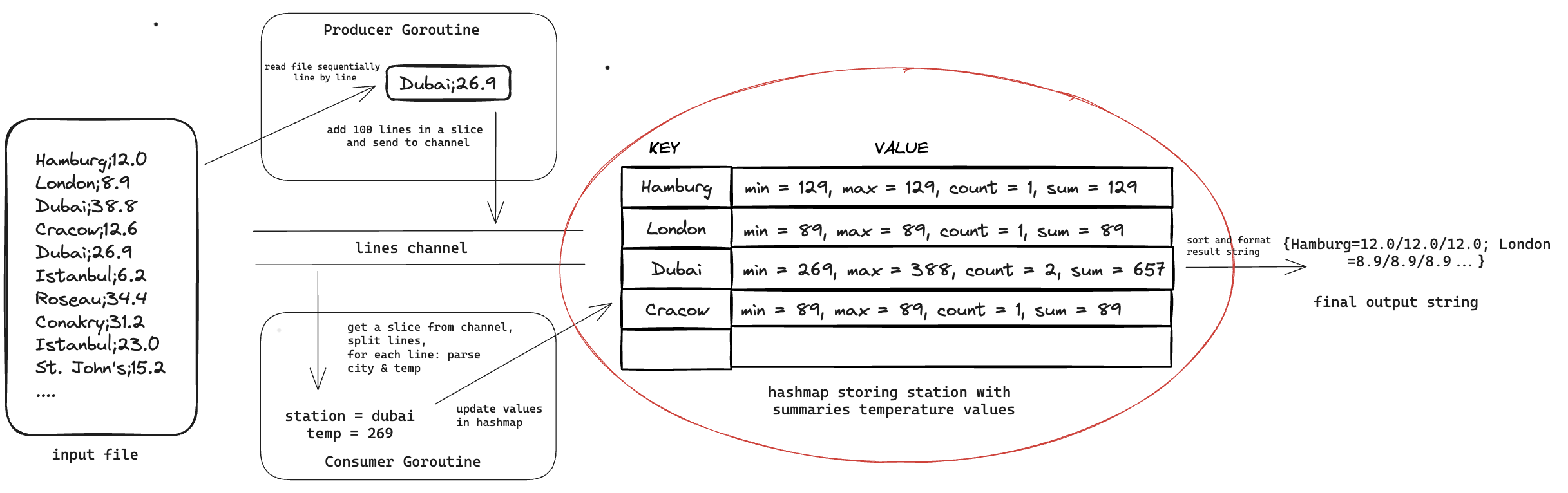
Making this change, the execution time went down by ~70s. Code and profiles till this point can be found here.
go run main.go 167.65s user 15.59s system 183% cpu 1:39.81 total
#5. Optimising all 3: Read chunks instead of one line at a time
Reading file: Read in chunks
In baseline implementation, we used bufio’s Scanner to read file contents line by line. While its a handy interface, it reads the file contents, performs some checks and then iterates over it to return a single line without the whitespace character in each Scan.
If we read the file in chunks, it will help improve performance in two ways:
- Single iterations over the bytes when parsing the city and temperature. We will avoid iterating over bytes that
Scannerinternally does to return a new line withScan. - Reduced number of items sent over channel. When sending 100 lines together in a string slice, we are sending 10,000,000 items (=1,000,000,000/100) over the channel. If we read a 64MB chunk from file and send it on the channel, that will be 256 items (=(16*1024)/64), a very significant reduction.
To process each chunk independently, it should end in a new line. We can do this in two ways:
- After a chunk is read, read till the next new line. Concatenate the two byte slice and send it on the channel.
- Slice the read byte slice till the last new line. The leftover chunk can be sent along with the next chunk read.
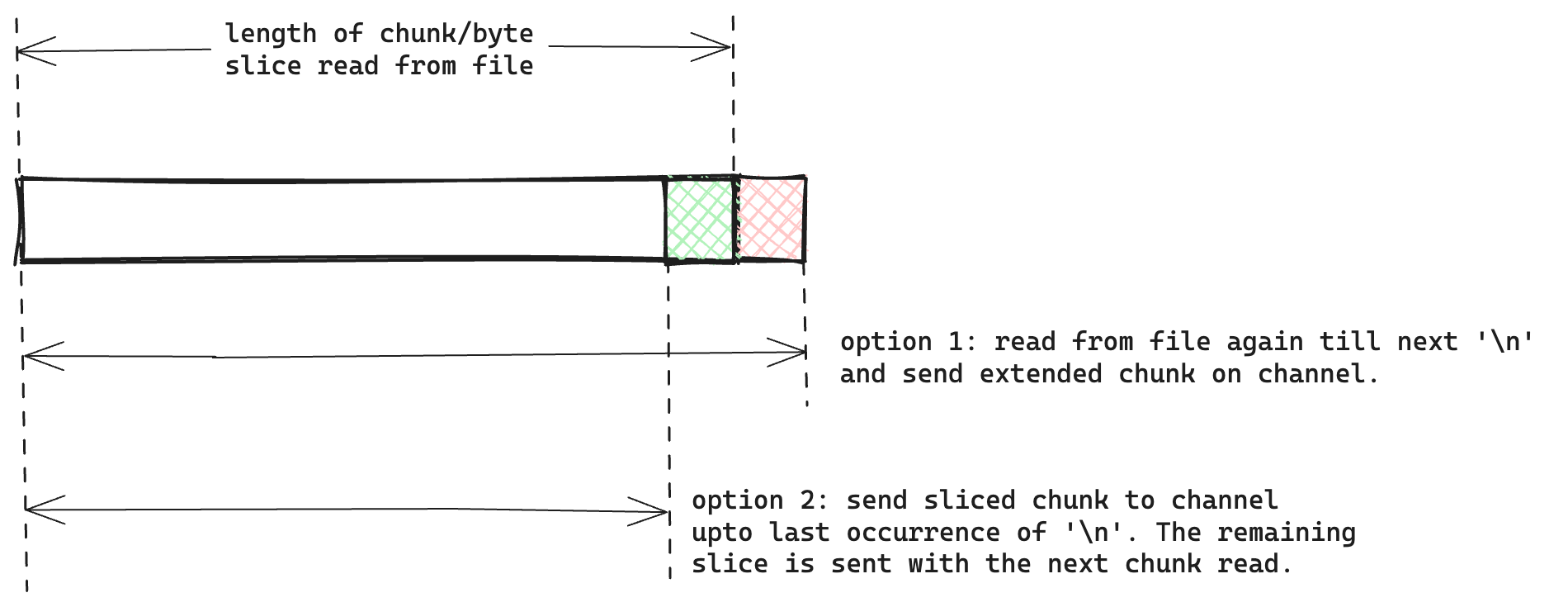
I first went with the first option as that was more clean to write and required less slice copying. To implement it, I decided to use a buffered I/O, bufio’s Reader. I read the file in 64MB chunks using Reader’s Read method. To read till the next new line character, I used ReadBytes method.
This did not improve performance as ReadBytes method again iterates over the characters to find the delimiter. But there’s something more.
Both, Scanner’s Scan method and Reader’s Read method, internally call os.Read. But as they provide more functionality beyond simply reading file, they do extra processing on top. Look at the implementation for each:
For our usecase, we don’t really need these convenient helper interfaces and can directly call the os.Read function.
Concurrency: Spin up more consumer goroutines
Since we are now sending chunks over the chunkChannel, the chunk consumer goroutines are first splitting the chunk into lines, processing each line and sending it to a lineChannel. The line consumer channel finally constructs the summarised map.
These chunk consumer goroutines can work in parallel as they are not adding values to the map directly. To take advantage of all CPU cores, I spun up (number of vCPU - 1) of chunk consumer goroutines, each concurrently taking chunks from channel, processing it and adding lines to lineChannel.
Data Structure: change line channel to map channel
Now, this alone will not improve performance as we just increased our memory footprint and the number of items being sent on channels:
- the file chunks send on the
chunkChannelconsumed by chunk consumer goroutines: 256 items (=(16*1024)/64). - the line slices sent over the
lineChannelto construct the final map: 10,000,000 items (=1,000,000,000/100).
Total number of items send and received from all channels comes around 10,000,256.
To reduce this, in each chunk consumer goroutine, we can process a chunk into a mini summarised map. This map can be sent to the map channel. The final map can be created by combining the mini summarised maps.
256 file chunks sent on chunkChannel + 256 mini summarised maps sent to mapsChannel = 512 items in total sent across channels!
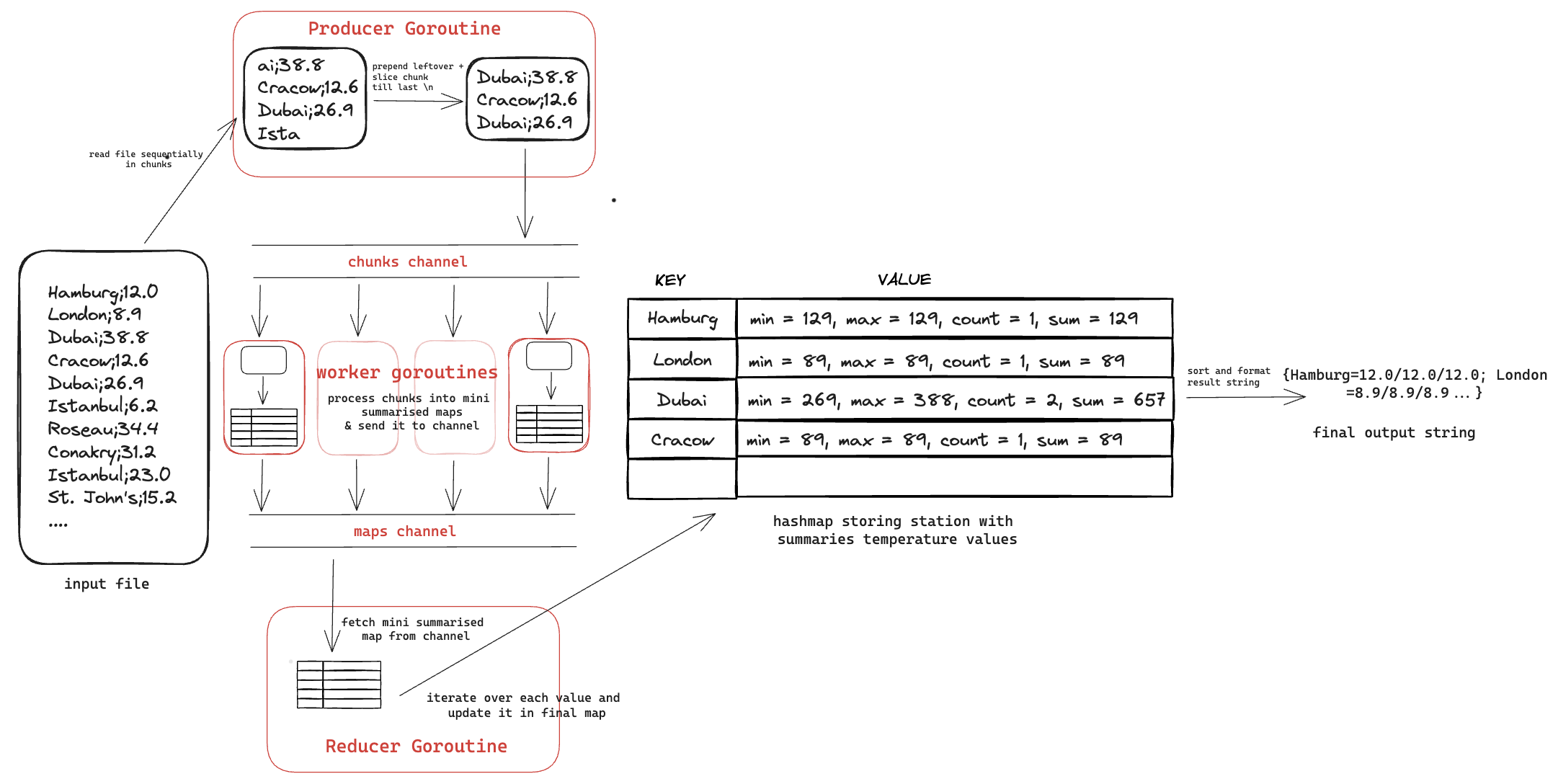
Implementing this, we are finally able to reduce the execution time to ~28s. Code is here.
go run main.go 193.42s user 14.04s system 762% cpu 28.544 total
#6. Improving string to int64 parsing
Looking at the flamegraph now we see that a considerable amount of time is going in convertStringToInt64 func.

Initially I was using strconv.ParseInt to convert string to int64. Looking at the implementation of strconv.ParseInt, it does a lot of checks that we don’t necessarily need ourselves.
Writing a custom string to int64 parser (which avoids concatenating the strings and some checks related to size) we reduce the execution time further to ~14s.
go run main.go 99.24s user 9.01s system 772% cpu 14.008 total
Further Optimisation Ideas
I only got this far within the challenge deadline, January 31st. There’s a lot more to explore here, some ideas:
- Looking at the latest CPU trace flamegraph, most of the time now seems to be going in map access and assign. Potential ways to optimise this:
- using numeric keys in map by encoding station names.
- replace inbuilt maps with faststring map or swiss maps.
- replace map usage with trie data structure.
- I hadn’t used unsafe so far because I wanted to see how far I can get without it (turns out a lot!).
mmapcan be used to get better results than I/O speed. Methods from Go’s unsafe package can also be used for string and byte manipulation.
And that’s a wrap!
I had a lot of fun working on this, massive shoutout to Gunnar Morling for putting this challenge together! I started with a rather unimpressive execution time of >6min and brought it down to 14s. Along the way I learned a tonne.
I found doing it iteratively and asking myself why a thing worked or didn’t work after every change helped me understand concepts more deeply than before. I also stand by reading Golang’s standard library code, I’ve found time and again its a great way to learn best practices and it never hurts to know whats really going on under the layers of abstractions.
If you also enjoyed doing this challenge, I’d love to chat, please do write to me on Twitter or on my mail: contact@shraddhaag.dev.
Resources
Internet is a treasure trove of resouces. I referred to a bunch of things when trying things out here, listing the most helpful ones here:
- First, Concurrency In Go by Katherine Cox-Buday is a gem of a book!
- I discovered the Google Group, golang-nuts, which has really interesting conversation where the language authors often chime in, eg -
- Golang benchmarks GitHub repo
- Is there any Performance benefit to use Int vs Float
- Floating point vs integer calculations on modern hardware
- Awesome read about Maps implementation by Dave Cheney.
- Understanding execution traces
- Found this really comprehensive blog about different ways to read files in Golang.
- Got to know about hyperfine to bechmark.